| Characteristic |
English
|
Spanish
|
||
|---|---|---|---|---|
| K N = 601 |
G1 N = 665 |
K N = 527 |
G1 N = 569 |
|
| Timepoint | ||||
| Spring 2023 | 0 (0%) | 0 (0%) | 527 (100%) | 569 (100%) |
| Fall 2023 | 598 (100%) | 663 (100%) | 0 (0%) | 0 (0%) |
| Fall 2024 | 3 (0.5%) | 2 (0.3%) | 0 (0%) | 0 (0%) |
| Administration Format | ||||
| CAT | 3 (0.5%) | 2 (0.3%) | ||
| Forms | 598 (100%) | 663 (100%) | 527 (100%) | 569 (100%) |
| Race | ||||
| American/Alaskan Native | 16 (2.7%) | 12 (1.8%) | 9 (1.8%) | 7 (1.3%) |
| Asian | 73 (12%) | 87 (13%) | 7 (1.4%) | 5 (0.9%) |
| Black/African American | 74 (13%) | 79 (12%) | 4 (0.8%) | 4 (0.7%) |
| Not reported | 132 (22%) | 127 (19%) | 353 (69%) | 366 (67%) |
| Other | 105 (18%) | 75 (11%) | 14 (2.7%) | 14 (2.6%) |
| White | 192 (32%) | 284 (43%) | 125 (24%) | 150 (27%) |
| Unknown | 9 | 1 | 15 | 23 |
| Ethnicity | ||||
| Hispanic/Latin(o/a) | 323 (54%) | 345 (52%) | 496 (97%) | 522 (96%) |
| Intentional nonreport | 10 (1.7%) | 3 (0.5%) | 0 (0%) | 1 (0.2%) |
| Not Hispanic/Latin(o/a) | 264 (44%) | 316 (48%) | 14 (2.7%) | 19 (3.5%) |
| Unknown | 4 | 1 | 17 | 27 |
| Gender | ||||
| Female | 305 (51%) | 317 (48%) | 307 (60%) | 325 (60%) |
| Male | 293 (49%) | 347 (52%) | 208 (40%) | 217 (40%) |
| Unknown | 3 | 1 | 12 | 27 |
| Home Language | ||||
| English | 416 (71%) | 493 (74%) | 75 (15%) | 70 (13%) |
| Spanish | 106 (18%) | 100 (15%) | 422 (82%) | 468 (86%) |
| Other | 63 (11%) | 69 (10%) | 15 (2.9%) | 6 (1.1%) |
| Unknown | 16 | 3 | 15 | 25 |
| English Proficiency Label | ||||
| (Re-)Classified Proficient | 38 (7.3%) | 61 (9.3%) | 44 (10.0%) | 42 (8.7%) |
| English Learner | 138 (26%) | 120 (18%) | 341 (77%) | 385 (80%) |
| English-only | 346 (66%) | 472 (72%) | 56 (13%) | 57 (12%) |
| Unknown | 79 | 12 | 86 | 85 |
| Ever IEP/504 | 36 (7.6%) | 62 (11%) | 27 (9.9%) | 23 (12%) |
| Unknown | 127 | 108 | 253 | 378 |
17 Nonword Repetition
17.1 Task Description
Children listen to nonsense words and are asked to repeat them verbatim.
17.2 Construct
The Nonword Repetition task measures the construct of auditory short-term memory. Students repeat a series of pseudowords of differing syllable length and complexity of sound combinations, thereby assessing linguistic abilities that have not been taught or learned previously and that are less culturally and linguistically biased.
17.3 Item Development
17.3.1 English
The constructed items followed the English phonotactic structure, featuring diverse syllable constructions that reflect the language’s phonological patterns. The length of the items ranged from one to five syllables. For each level of number of syllables, a mix of light and heavy items was developed based on phoneme density. We conceptualized nonwords as light when less than half of the syllables contained complex onsets or codas and had no diphthongs. Light items used the following syllable patterns: CVC, CV, and/or VC. We conceptualized nonwords as heavy when more than half of the syllables contain complex onsets or codas, or a diphthong. Heavy items used the following syllable patterns: CCVC, CCVCC, CVVC, and/or CVCC.
Dialectal considerations. To avoid possible mis-scoring due to a lack of consideration of dialectal differences, we avoided using word-final “th” in item development, as it is can often fronted (“breve” for “breathe”) or stopped (“wit” for “with”) in African American English and in English influenced by other languages. We also avoided clusters of nasals and stops (/nt/). Additionally, proctors were instructed to be cognizant that voiced word-final consonants can be devoiced and/or spirantized in some dialects (e.g., “bed” as “beth” or “bet”) and should be scored as correct.
17.3.2 Spanish
The constructed items followed the Spanish phonotactic structure, featuring diverse syllable constructions that reflect the language’s phonological patterns. The length of the items ranged from two-syllable nonwords with five or six phonemes to five-syllable nonwords of 11 to 13 phonemes in length. Given the scarcity of one-syllable words in Spanish, the task started at two-syllable words, in line with existing nonword repetition tasks. For the blueprint used for item development, see Table 17.1.
| Number of syllables | CV structure | Nonword example |
|---|---|---|
| Two syllable nonwords | CV CVC | g a u β e ɾ |
| CVC CV | m e ɾ ɣ u i | |
| CVC CV | t i ŋ k u a | |
| CVC CVC | m e ɾ f a s | |
| Three syllable nonwords | CV CV CV | ɾ u tʃ e t u a |
| CV CV CV | tʃ e ɾ u ɣ u a | |
| CVC CV CVC | t i n tʃ a u β e l | |
| CVC CV CVC | d u ɾ b i e p o s | |
| Four syllable nonwords | CV CV CV CV | k i tʃ e ɾ u p i a |
| CV CV CV CV | f i ɾ u tʃ e p i a | |
| CV CV CV CVC | m a ʊ t e i p o i t i n | |
| CV CVC CV CVC | m e ɾ a n tʃ u t i n | |
| Five syllable nonwords | CVC CV CV CV CV | b i ŋ k u a m i ɛ f e ɣ u i |
| CVC CVC CV CV CV | h u s t i n r u n a i tʃ e | |
| CV CVC CV CV CVC | n u e β u r d a i ɣ u i p o s | |
| CVC CV CV CVC CVC | p e n tʃ u f a i t i n β e l |
17.4 Scoring
Dichotomous fixed response format of 0 points for incorrect responses or non-responses and 1 point for correct ones.
17.5 Calibration Samples
17.6 Psychometric Analysis
17.6.1 Basic Item Statistics
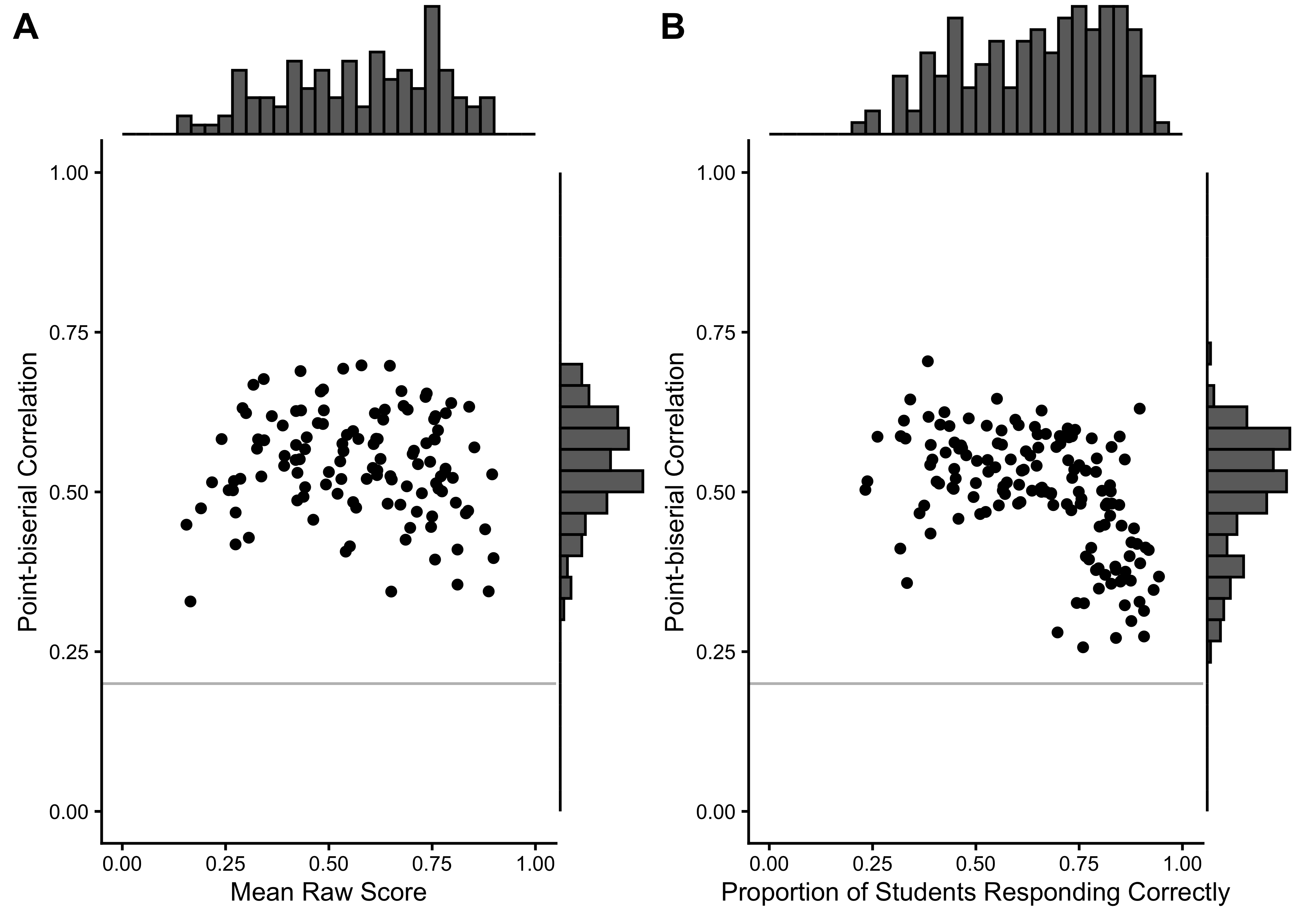
We excluded 0 items from the English task and 0 items from the Spanish task based on low response counts (n < 90). 0 items were excluded because they had no variance in the Spanish task, and 0 items in the English task. Additionally, we excluded 0 items from the English task and 0 items from the Spanish task based on low point-biserial correlations (r < 0.2). Table 17.3 summarizes the basic item characteristics, Figure 17.1 shows the relationship between point-biserial correlations and the proportion of correct responses for each item.
English
|
Spanish
|
|||
|---|---|---|---|---|
| Characteristic |
Before Excl.
|
After Excl.
|
Before Excl.
|
After Excl.
|
| N = 118 | N = 118 | N = 145 | N = 145 | |
| No. of Responses | 178 (139) | 178 (139) | 142 (103) | 142 (103) |
| Proportion Correct | 0.57 (0.19) | 0.57 (0.19) | 0.65 (0.18) | 0.65 (0.18) |
| Point-biserial Correlation | 0.54 (0.08) | 0.54 (0.08) | 0.50 (0.09) | 0.50 (0.09) |
| Excluded (n < 90) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Excluded (pbis < .2) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Excluded (no variation) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
17.6.2 Rasch Analysis
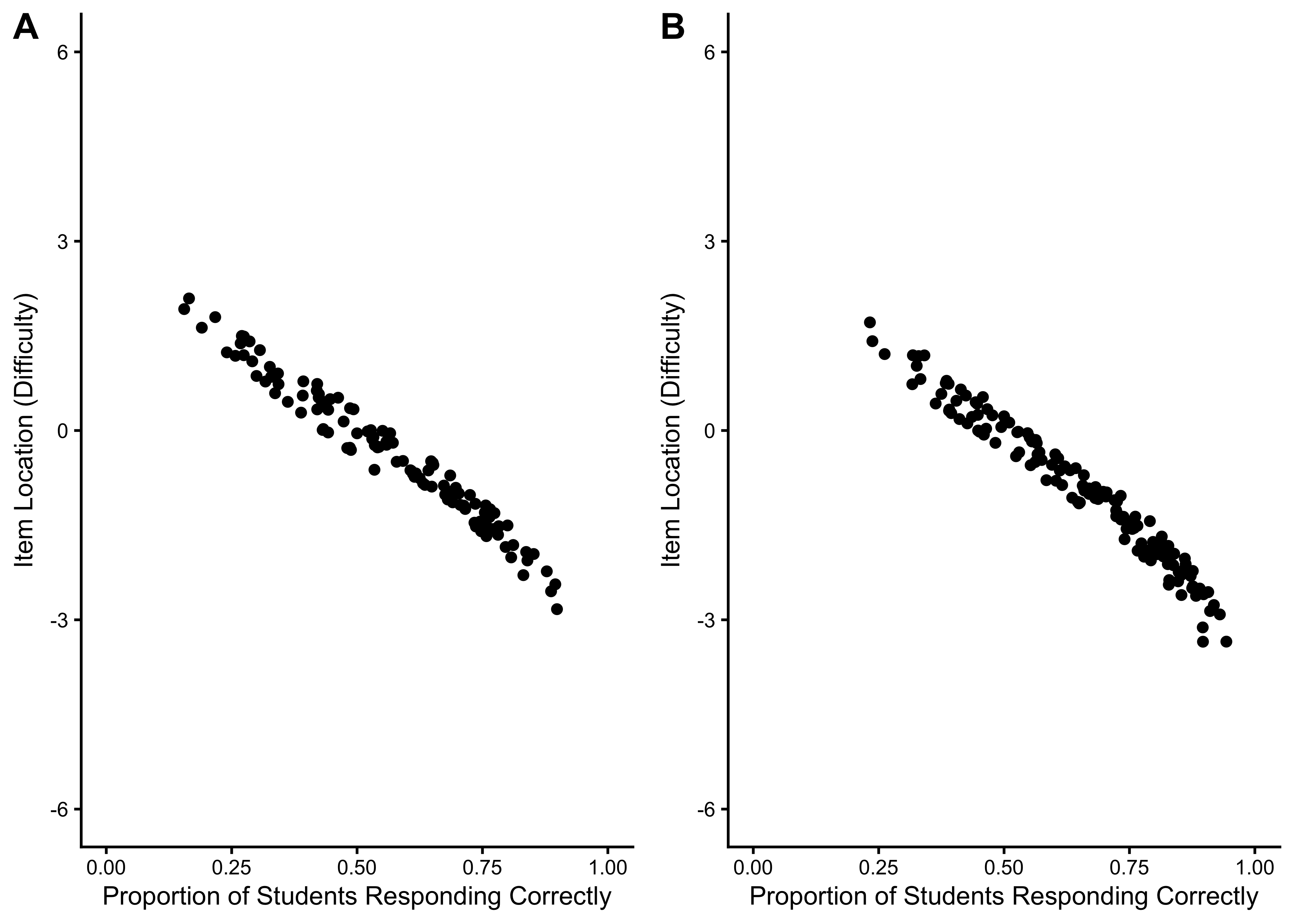
17.6.2.1 Item Location Estimates
17.6.2.2 Item Fit Statistics
| A | B | C | D | Total | A | B | C | D | Total | |
|---|---|---|---|---|---|---|---|---|---|---|
| Outfit MSE | ||||||||||
| A | 117 | 0 | 0 | 0 | 117 | 137 | 0 | 0 | 0 | 137 |
| B | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C | 1 | 0 | 0 | 0 | 1 | 8 | 0 | 0 | 0 | 8 |
| D | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Total | 118 | 0 | 0 | 0 | 118 | 145 | 0 | 0 | 0 | 145 |
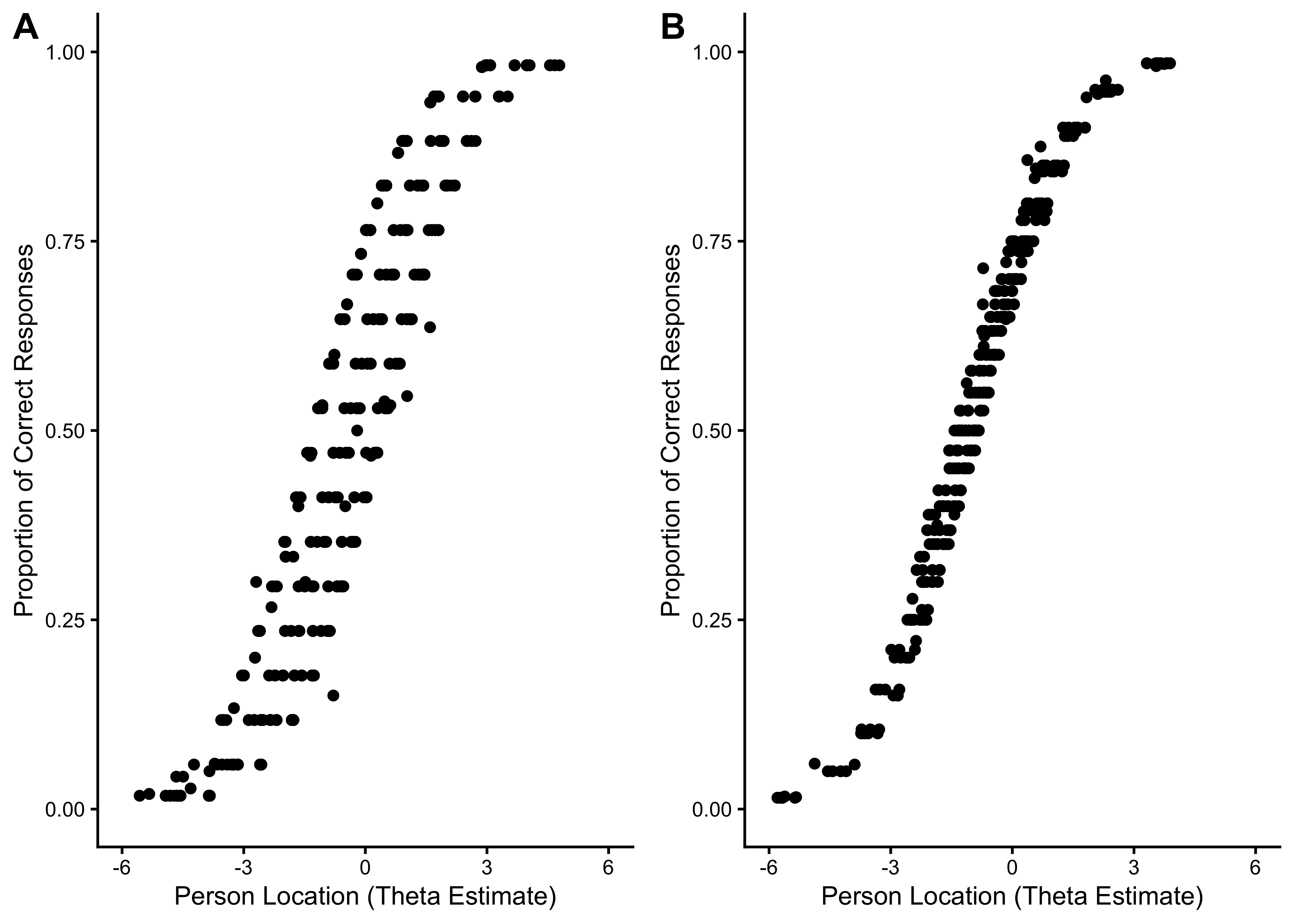
17.6.2.3 Person Location Estimates
17.6.2.4 Person Fit Statistics
| A | B | C | D | Total | A | B | C | D | Total | |
|---|---|---|---|---|---|---|---|---|---|---|
| Outfit MSE | ||||||||||
| A | 994 | 0 | 1 | 0 | 995 | 780 | 0 | 0 | 0 | 780 |
| B | 90 | 119 | 0 | 0 | 209 | 112 | 101 | 0 | 0 | 213 |
| C | 40 | 0 | 8 | 0 | 48 | 39 | 0 | 13 | 0 | 52 |
| D | 4 | 0 | 2 | 0 | 6 | 11 | 0 | 5 | 0 | 16 |
| Total | 1,128 | 119 | 11 | 0 | 1,258 | 942 | 101 | 18 | 0 | 1,061 |
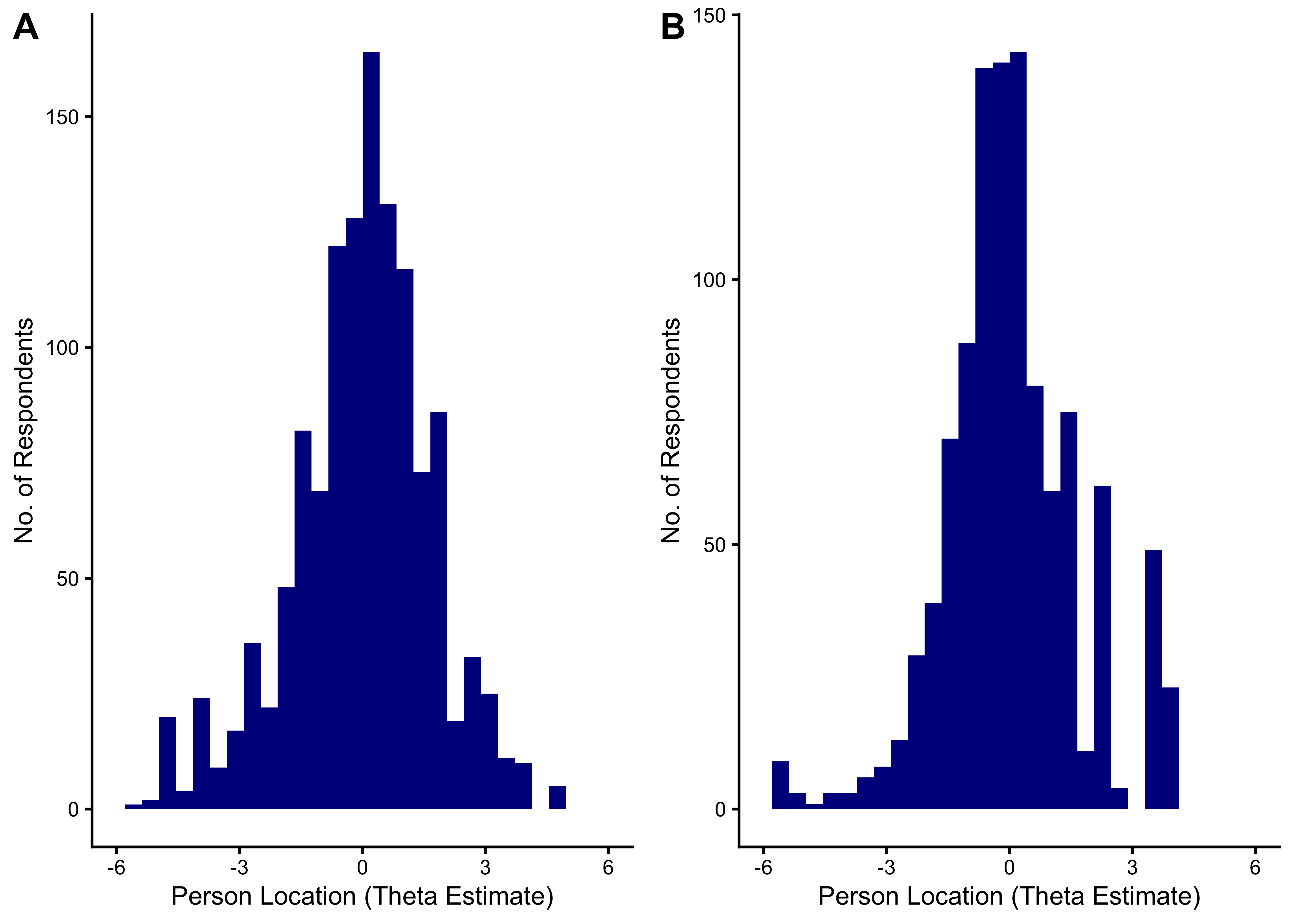
17.6.2.5 Distribution of Theta Estimates
17.6.2.6 Wright Maps
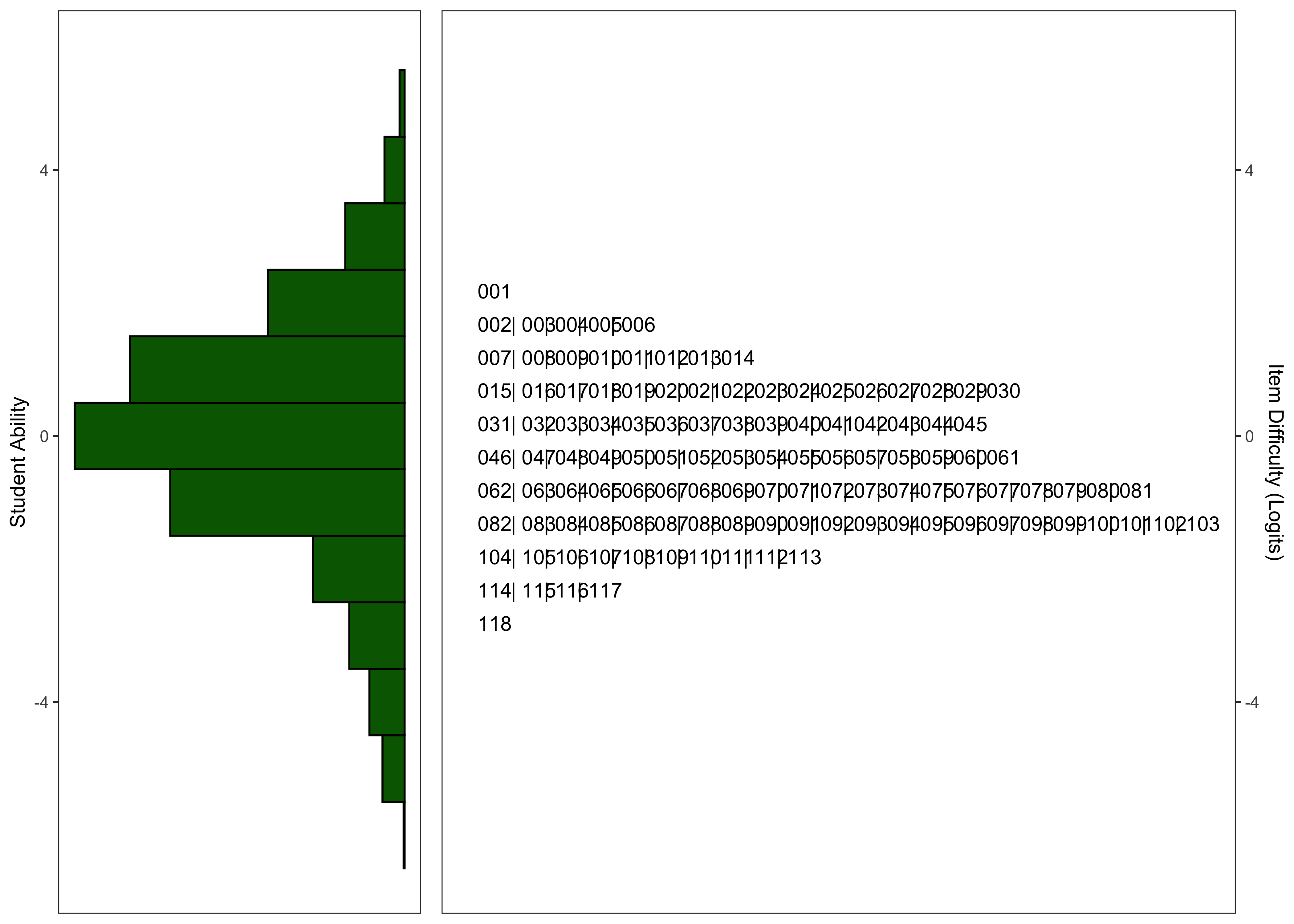
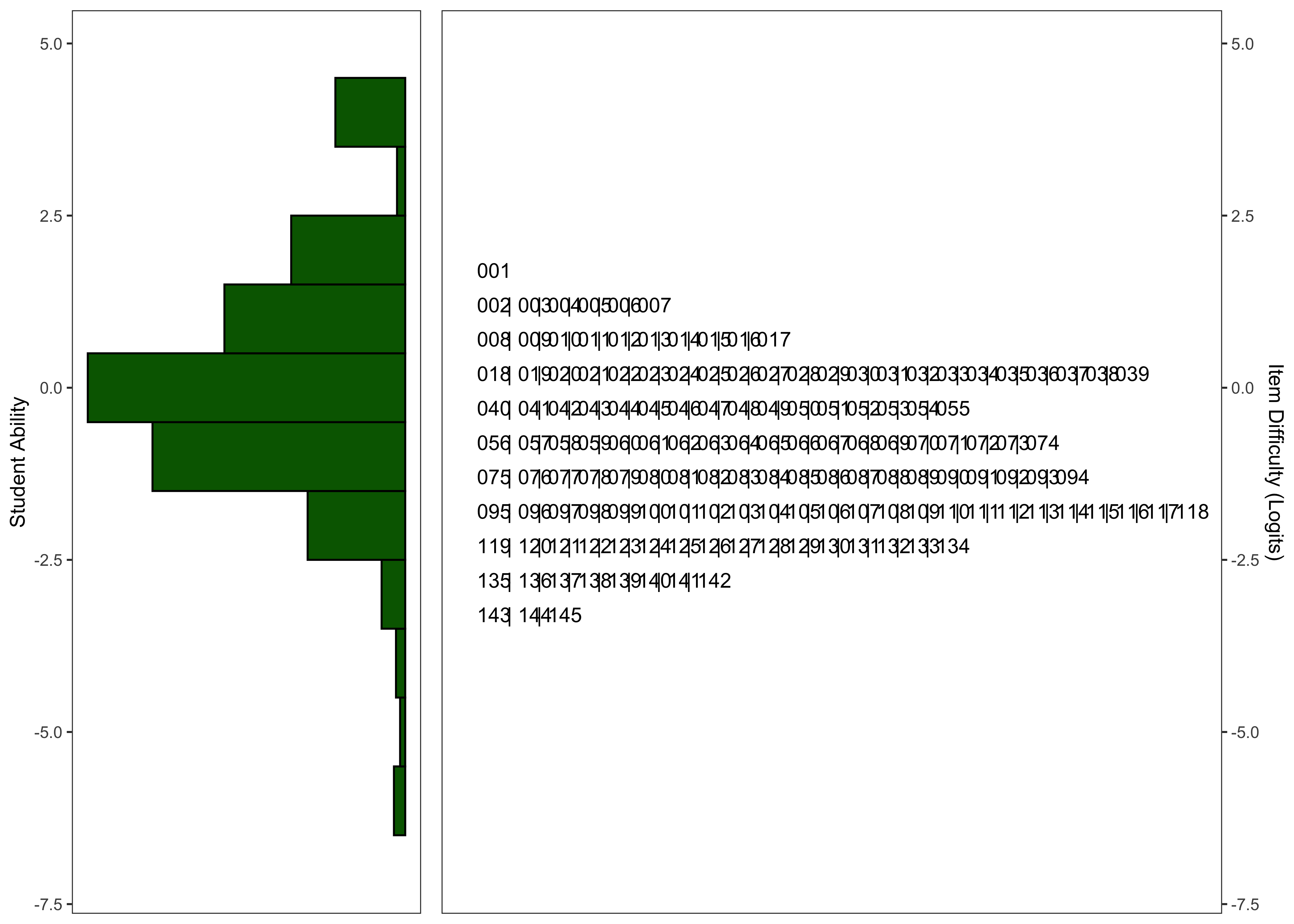
17.6.2.7 Model Summary
| Characteristic | N = 118 | N = 1,258 | N = 145 | N = 1,061 |
|---|---|---|---|---|
| Logit Scale Location | -0.41 (1.09) | 0.05 (-0.89, 1.02) | -0.95 (1.14) | -0.07 (-0.90, 0.96) |
| Outfit | 0.98 (0.18) | 0.84 (0.63, 1.04) | 1.01 (0.23) | 0.81 (0.57, 1.11) |
| Infit | 0.99 (0.09) | 0.90 (0.77, 1.04) | 1.00 (0.10) | 0.89 (0.74, 1.06) |
| Reliability of Separation | 0.8244 | 0.7596 | 0.8272 | 0.7669 |
17.6.2.7.1 Final Number of Items
Following the exclusion of items with point-biserial correlations < .20 and items with poor fit statistics, the final versions of the task contain 118 and 145 for the English and Spanish task, respectively.
17.7 Criterion Validity Evidence
17.7.1 Sample
| Characteristic |
English
|
Spanish
|
||
|---|---|---|---|---|
| K N = 251 |
G1 N = 215 |
K N = 236 |
G1 N = 221 |
|
| Timepoint | ||||
| Winter 2024 | 251 (100%) | 215 (100%) | 236 (100%) | 221 (100%) |
| Race | ||||
| American/Alaskan Native | 5 (2.0%) | 3 (1.4%) | 2 (0.9%) | 4 (1.8%) |
| Asian | 36 (15%) | 35 (16%) | 8 (3.4%) | 2 (0.9%) |
| Black/African American | 25 (10%) | 26 (12%) | 1 (0.4%) | 0 (0%) |
| Not reported | 28 (11%) | 29 (13%) | 130 (56%) | 149 (68%) |
| Other | 71 (29%) | 44 (20%) | 38 (16%) | 8 (3.7%) |
| White | 83 (33%) | 78 (36%) | 55 (24%) | 55 (25%) |
| Unknown | 3 | 0 | 2 | 3 |
| Ethnicity | ||||
| Hispanic/Latin(o/a) | 99 (39%) | 91 (42%) | 214 (92%) | 205 (93%) |
| Intentional nonreport | 7 (2.8%) | 2 (0.9%) | 1 (0.4%) | 0 (0%) |
| Not Hispanic/Latin(o/a) | 145 (58%) | 122 (57%) | 18 (7.7%) | 16 (7.2%) |
| Gender | ||||
| Female | 124 (49%) | 97 (45%) | 124 (53%) | 108 (49%) |
| Male | 127 (51%) | 118 (55%) | 112 (47%) | 113 (51%) |
| Home Language | ||||
| English | 183 (74%) | 159 (74%) | 28 (12%) | 21 (9.6%) |
| Spanish | 31 (13%) | 24 (11%) | 203 (87%) | 196 (90%) |
| Other | 32 (13%) | 31 (14%) | 2 (0.9%) | 1 (0.5%) |
| Unknown | 5 | 1 | 3 | 3 |
| English Proficiency Label | ||||
| (Re-)Classified Proficient | 11 (5.4%) | 17 (8.1%) | 31 (14%) | 24 (11%) |
| English Learner | 47 (23%) | 39 (19%) | 180 (81%) | 174 (81%) |
| English-only | 147 (72%) | 154 (73%) | 10 (4.5%) | 17 (7.9%) |
| Unknown | 46 | 5 | 15 | 6 |
| Ever IEP/504 | 18 (9.4%) | 21 (13%) | 20 (9.7%) | 23 (11%) |
| Unknown | 59 | 47 | 29 | 12 |
| Unknown | 3 | 0 | ||
English Nonword Repetition was correlated with the Nonword Repetition subtest from the Woodcock-Johnson IV (WJ IV COG) test (Schrank, McGrew, and Mather 2014). Spanish Nonword Repetition was correlated with the Repetición de Palabras Sin Sentido subtest from the Batería IV Woodcock-Muñoz (Batería IV COG) test (Woodcock et al. 2019).
| Grade | n | r [CI] | n | r [CI] | n | r [CI] |
|---|---|---|---|---|---|---|
| K | 251 | 0.45 [0.34, 0.54] | 47 | 0.25 [-0.04, 0.50] | 236 | 0.49 [0.38, 0.58] |
| G1 | 215 | 0.53 [0.42, 0.62] | 39 | 0.60 [0.35, 0.77] | 221 | 0.48 [0.37, 0.57] |